Value Iteration
Value Iteration
VI is one of the fundamental algorithms for planning. Many RL algorithms are essentially the sample-based variants of VI (DQN). We directly use the results of fixed points proposition and contraction property of the Bellman operator we proved in Bellman Optimality Equations.
Idea
Starting from \(V_0 \in B(X)\), we compute a sequence of \((V_{k})_{k \geq 0}\) by:
\[V_{k+1} \leftarrow T^{\pi} V_{k}\]
By the contraction property of the Bellman operator and Uniqueness of fixed points proposition :
\[lim_{k \rightarrow \infty} \| V_k - V^{\pi}\|_{\infty} = 0\]
similar for \(Q\):
\[lim_{k \rightarrow \infty} \| Q_k - Q^{\pi}\|_{\infty} = 0\]
Also, if we compute a sequence of \((V_{k})_{k \geq 0}\) by:
\[V_{k+1} \leftarrow T^{*} V_{k}\]
\[Q_{k+1} \leftarrow T^{*} Q_{k}\]
By the contraction property of the Bellman operator and Uniqueness of fixed points proposition, it is guaranteed that
\[lim_{k \rightarrow \infty} \| V_k - V^{*}\|_{\infty} = 0\]
\[lim_{k \rightarrow \infty} \| Q_k - Q^{*}\|_{\infty} = 0\]
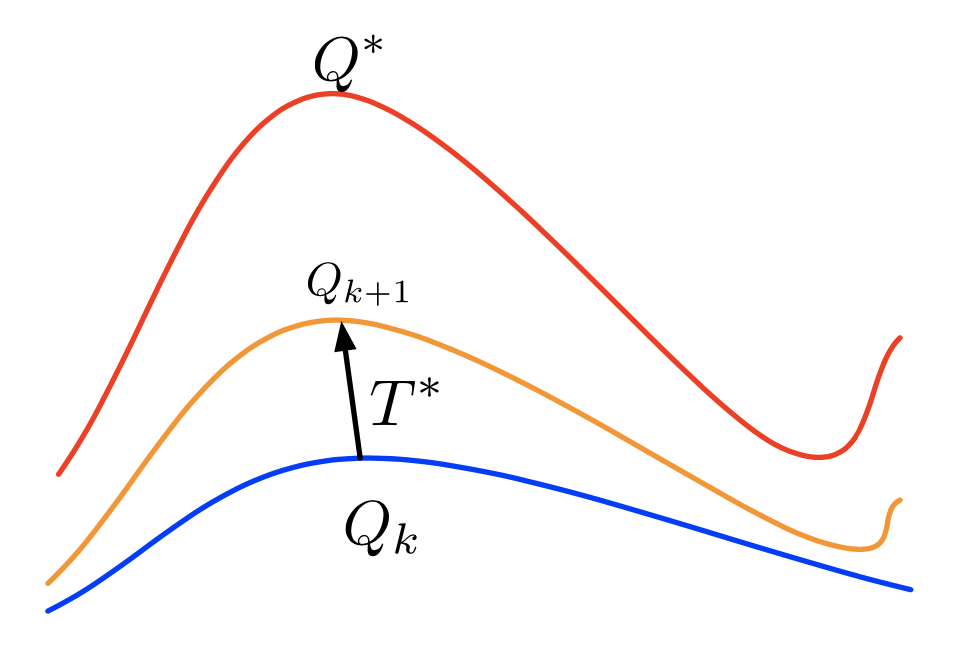
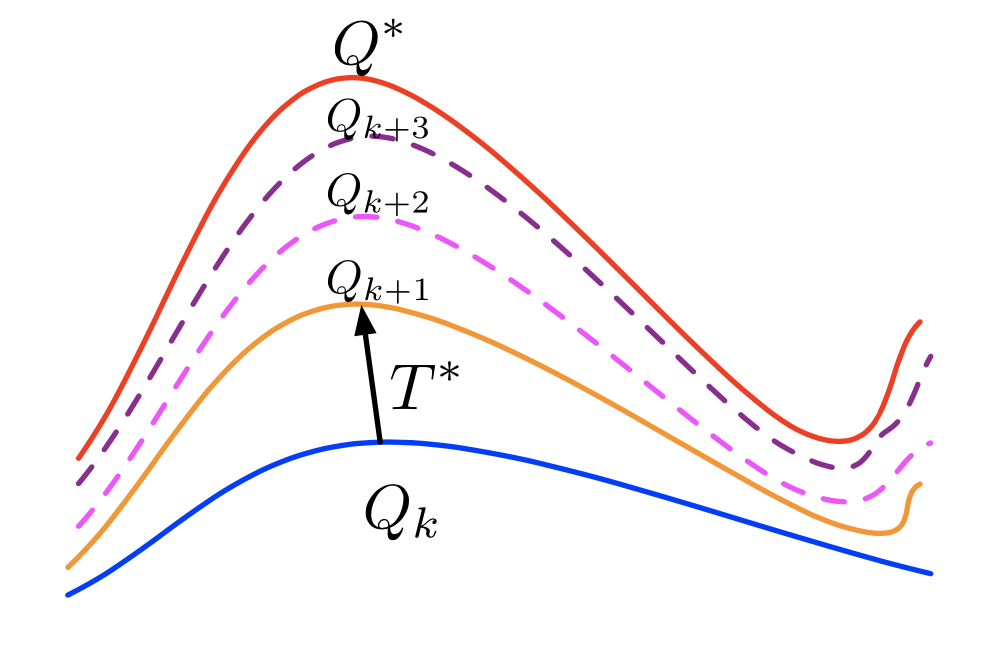
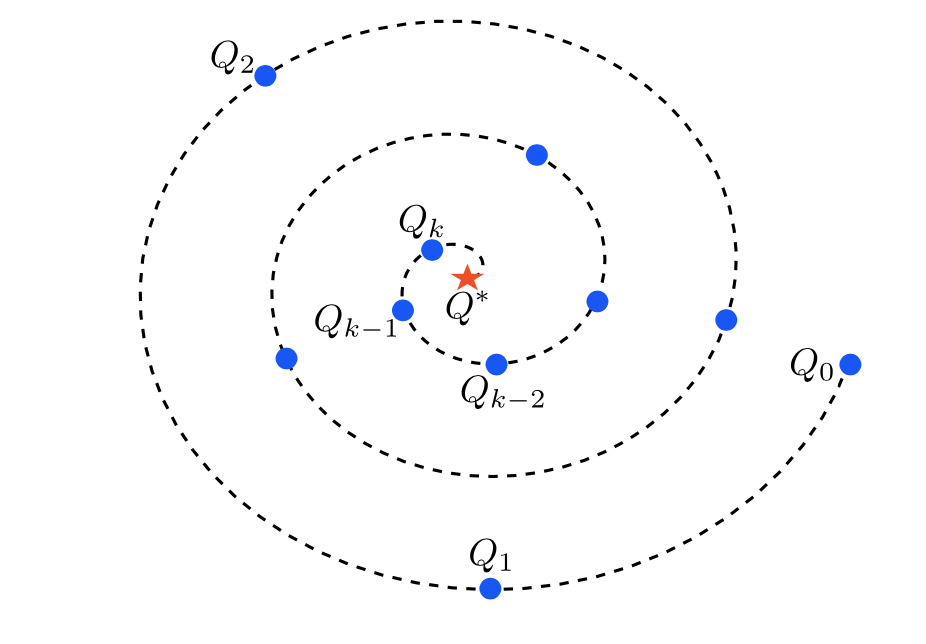
After finding \(Q^{*}\), finding optimal policy is straightforward:
\[\pi^{*} (a | x) = argmax_{a \in A} Q^{*} (x, a)\]
algorithm
One generic implementation can be found in intro to RL book:

Implementation
Below is one implementation of Value iteration (using Q):
1 | # part of code from rl-algo.dp |