DDQN
Deep Reinforcement Learning with Double Q-Learning
Introduction
The authors show that the double Q-learning algorithm which was first proposed in a tabular setting, can be generalized to arbitrary function approximation, including DNN. They use this to construct a new algorithm called double DQN to solve the overestimation problem in DQN.
Notations
Define:
\[Q_{\pi} (s, a) = E[R_1 + \gamma R_2 + ... | S_0=s, A_0=a, \pi]\]
\[Q_{*} (s, a) = max_{\pi} Q_{\pi} (s, a)\]
\[\pi_{*} (s) = argmax_{a \in A} Q_{*} (s, a)\]
The Target:
\[Y_t^{Q} = R_{t+1} + \gamma max_{a} Q(S_{t+1}, a; \theta_{t})\]
A standard Q update using stochastic gradient decent is (Semi-gradient Q):
\[\theta_{t+1} = \theta_t + \alpha (Y_{t}^{Q} - Q(S_t, A_t; \theta_t)) \nabla_{\theta_t} Q(S_t, A_t; \theta_t)\]
Where \(\alpha\) is a scalar step size.
Background
Double Q-learning
The max operator in standard Q-learning and DQN uses the same values both to select and to evaluate an action (ie. same Q is used to select the max action and use the value of this max action to update the Value of the state action pair). This makes it more likely to select overestimated values, resulting in overoptimistic value estimates.
In Double Q-learning, two value functions are learned by assigning experiences randomly to update one of the two value functions, resulting in two sets of weights, \(\theta\) and \(\theta^{\prime}\). For each update, one set of weights is used to determine the greedy action, and the other to determine its value.
Previous Q target:
\[Y_t^{Q} = R_{t+1} + \gamma Q(S_{t+1}, argmax_{a \in A} Q(S_{t+1}, a; \boldsymbol{\theta_t}); \boldsymbol{\theta_{t}})\]
The double Q-learning target:
\[Y_t^{\text{DoubleQ}} = R_{t+1} + \gamma Q(S_{t+1}, argmax_{a \in A} Q(S_{t+1}, a; \boldsymbol{\theta_t}); \boldsymbol{\theta^{\prime}_{t}})\]
Maximization Problem

This theorem shows that even if the value estimates are on average correct, estimation errors of any source can drive the estimates up and away from the true optimal values.
The lower bound in Theorem 1 decreases with the number of actions. This is an artifact of considering the lower bound, which requires very specific values to be attained. More typically, the overoptimism increases with the number of actions.
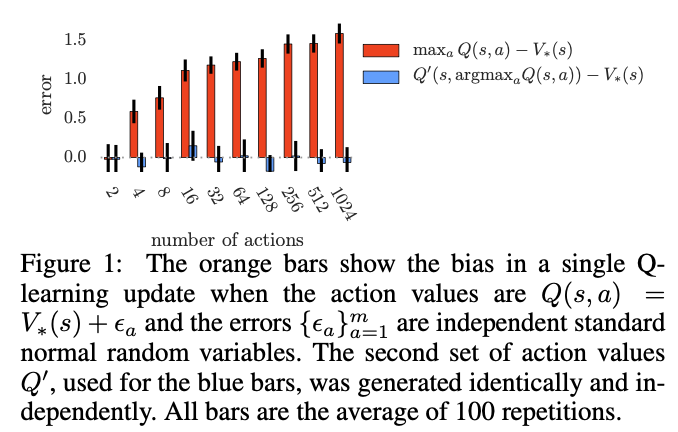
\[E[Q(s, a) - V_{*}(s)] = E[V_{*}(s) - V_{*}(s) + \epsilon ] = 0\]
But, Q-learning updates have large bias due to max operation, the phenomena is severer as number of actions increases.
In function approximation setting:
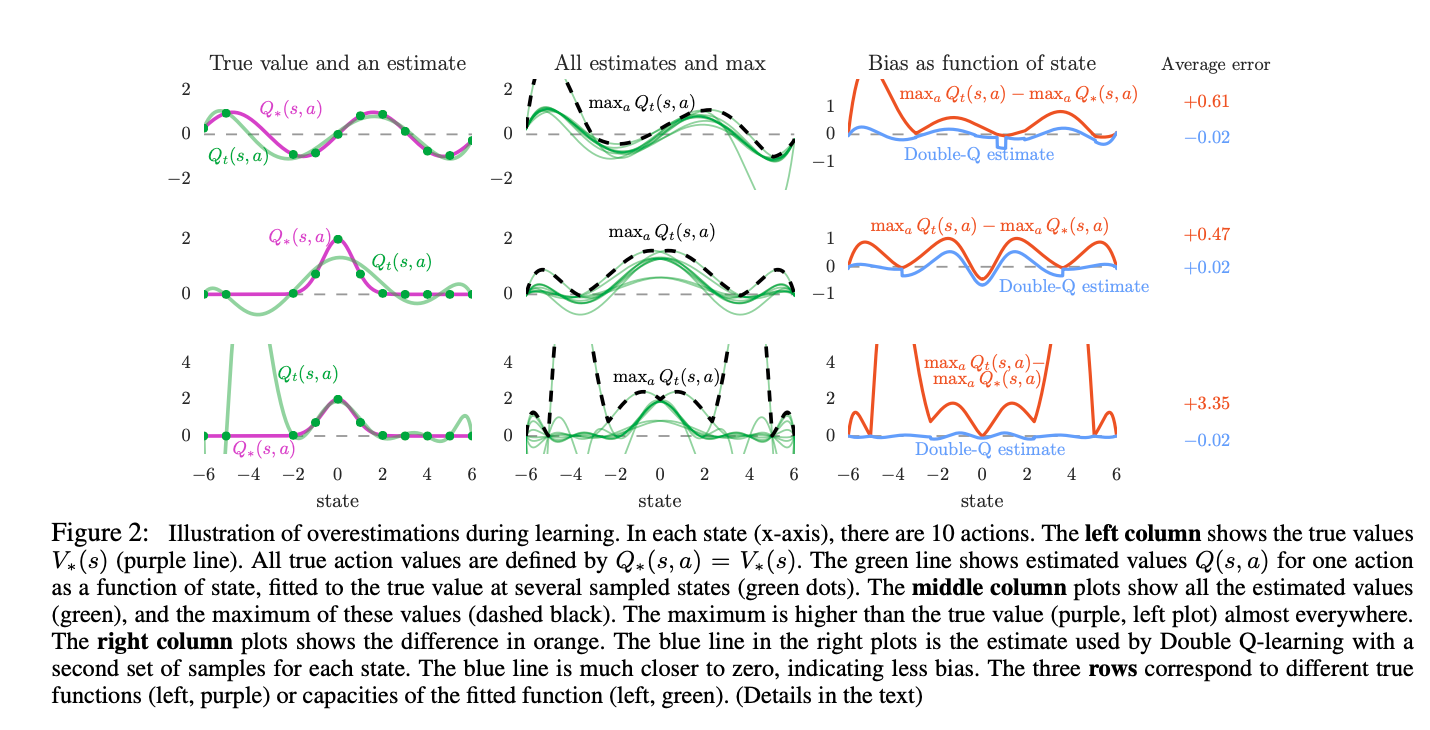
Algorithm
The target network in the DQN architecture provides a natural candidate for the second value function, without having to introduce additional networks. Thus, we can evaluate the greedy policy according to the online network, but using the target network to estimate its value. The resulting update:
\[Y_t^{\text{DoubleDQN}} = R_{t+1} + \gamma Q(S_{t+1}, argmax_{a} Q(S_{t+1}, a; \theta_{t}), \theta_{t}^{-})\]
Implementation
This is an implementation of DDQN in PARL. This implementation is written using PaddlePaddle.
https://github.com/PaddlePaddle/PARL
1 | # Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved. |