Dropout
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
The key idea of drop out is to randomly drop units along with their connections from the neural network during training to prevent overfitting. It can be interpreted as a way of regularizing a NN by adding noise to its hidden units.
Introduction
With unlimited computation, the best way to "regularize" a fixed-sized model is to average the predictions of all possible settings of the parameters, weighting each setting by the posterior probability given the training data (\(P(\theta | X)\)). This approach is not feasible in real life especially when there is large computational cost for training neural networks and training data are limited.Dropout prevents overfitting and provides a way of approximately combining exponentially many neural network architectures effectively.
Dropout temporarily removes units from the network along with all their incoming and outgoing connections. The choice of which units to drop is random.
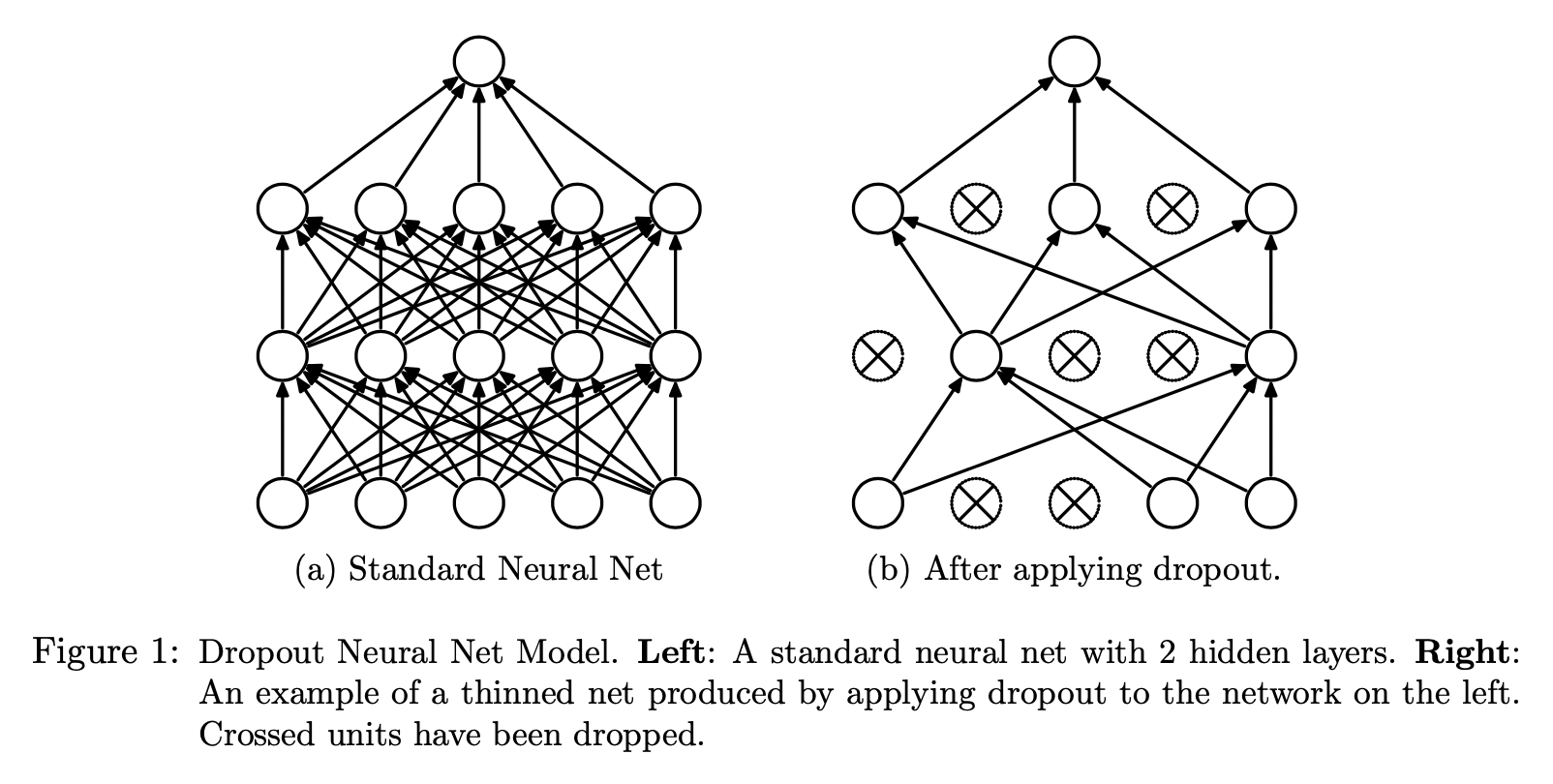
At training time, for a NN with \(n\) units, Dropout can be seen as training a collection of \(2^n\) (each unit can be retained or removed by dropout, so \(2^n\) different combinations) thinned networks (some units are dropped by dropout) with extensive weight sharing where each thinned network gets trained very rarely.
At test time, it is not feasible to explicitly average the predictions form exponentially many thinned models. However, we use a single NN without dropout by scaling-down the weights of this network. If an unit is retained with probability \(p\) during traning, the outgoing weights of that unit are multiplied by \(p\) at the test time. This ensures that the expected output is the same as the actual output at the test time (we use expected output at test time).
