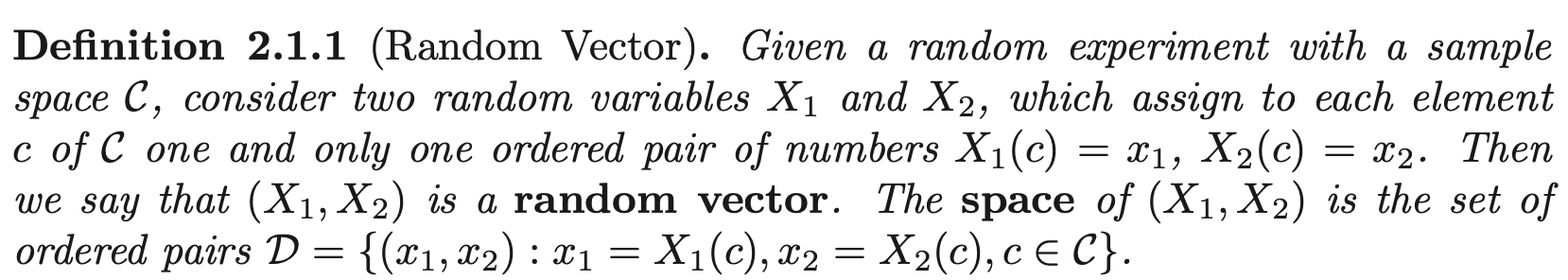Calculus (1)
Multivariate Calculus (1)
Fundamental Theorem of Calculus
If \(f\) is continuous and \(F\) is indefinite integral of \(f\) (i.e \(F^{\prime} = f\) or \(\int f(x) dx = F(x) + c\), without bounds) on closed interval \([a, b]\), then:
- \(\int^{b}_{a} f(x) dx = F(b) - F(a)\)
- \(\frac{d}{dx}\int^{x}_{a} f(t)dt = F^{\prime}(x) - F^{\prime}(a) = F^{\prime} (x) = f(x)\)
Definition of Integral
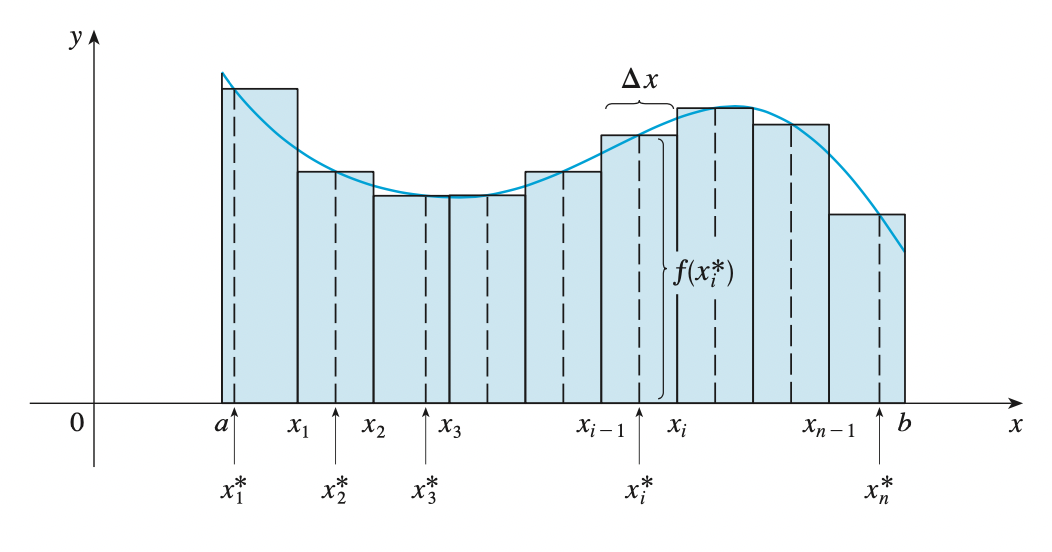
If \(f(x)\) is defined for \(a \leq x \leq b\), we start by dividing the interval \([a, b]\) into \(n\) sub-intervals \([x_{i - 1}, x_{i}]\) of equal width \(\Delta x = \frac{b - a}{n}\) and we choose sample points \(x^{*}_i\) in these subintervals. Then we form the Riemann sum:
\[\sum^{n}_{i=1} f(x^{*}_n) \Delta x\]
Then by taking the limit \(n \rightarrow \infty\), we have the definite integral of \(f\) from \(a\) to \(b\):
\[\int^{b}_{a} f(x) dx = \lim_{n \rightarrow \infty} \sum^{n}_{i=1} f(x^{*}_n) \Delta x\]
In the special case where \(f(x) \leq 0\), we can interpret the Riemann sum as the sum of the areas of the approximating rectangles, and \(\int^{b}_{a} f(x) dx\) represents the area under the curve \(y = f(x)\) from \(a\) to \(b\).
Vectors and the Geometric of Space
Equation of a sphere
By definition, a sphere is the set of all points \(P(x, y, z)\) whose distance from \(C\) is \(r\), where \(C\) is the center \(C(h, k, l)\). Thus, \(P\) is on the sphere if and only if
\[|PC| = r \implies |PC|^2 = r^2\]
\[(x - h)^2 + (y - k)^2 + (z - l)^2 = r^2\]