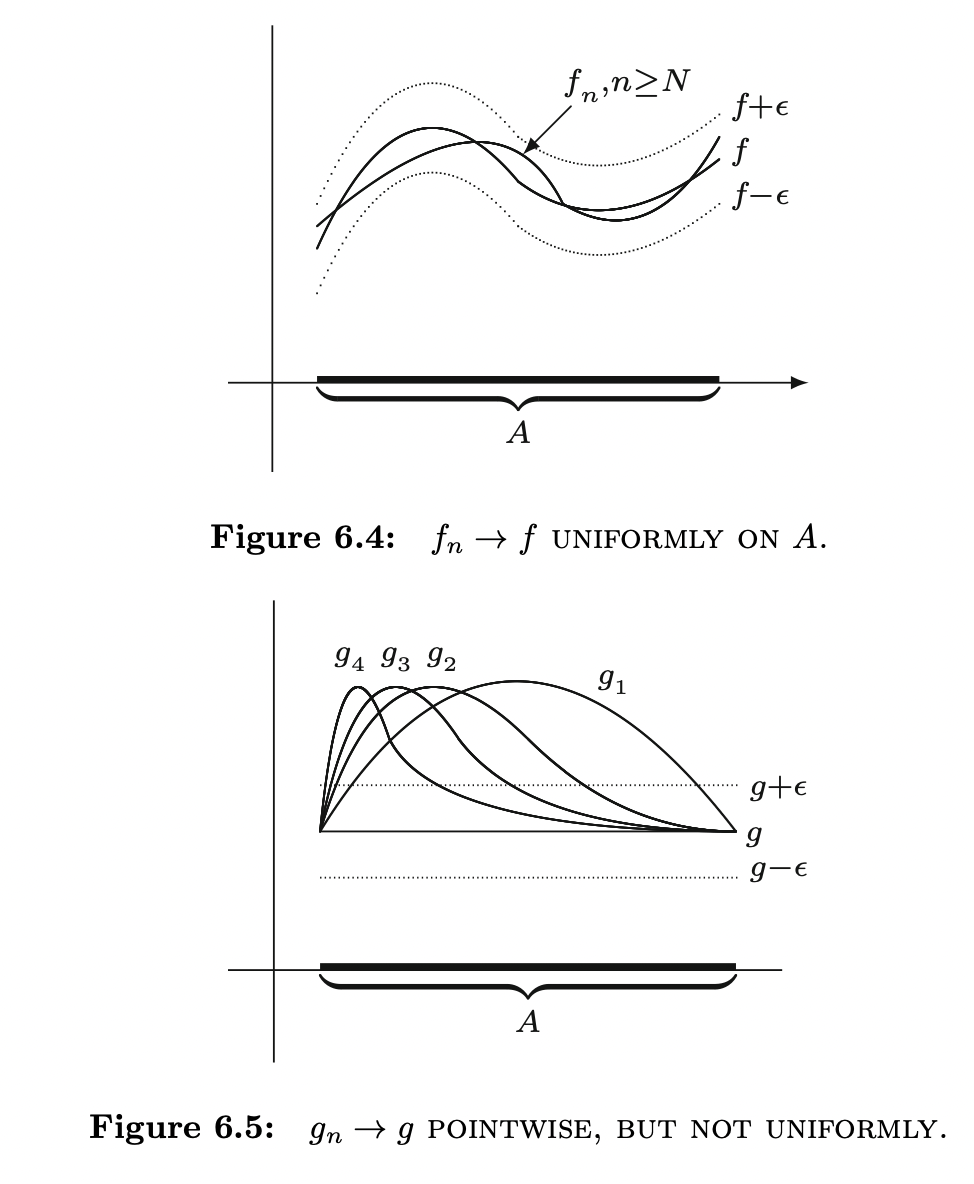
Attention is all you need
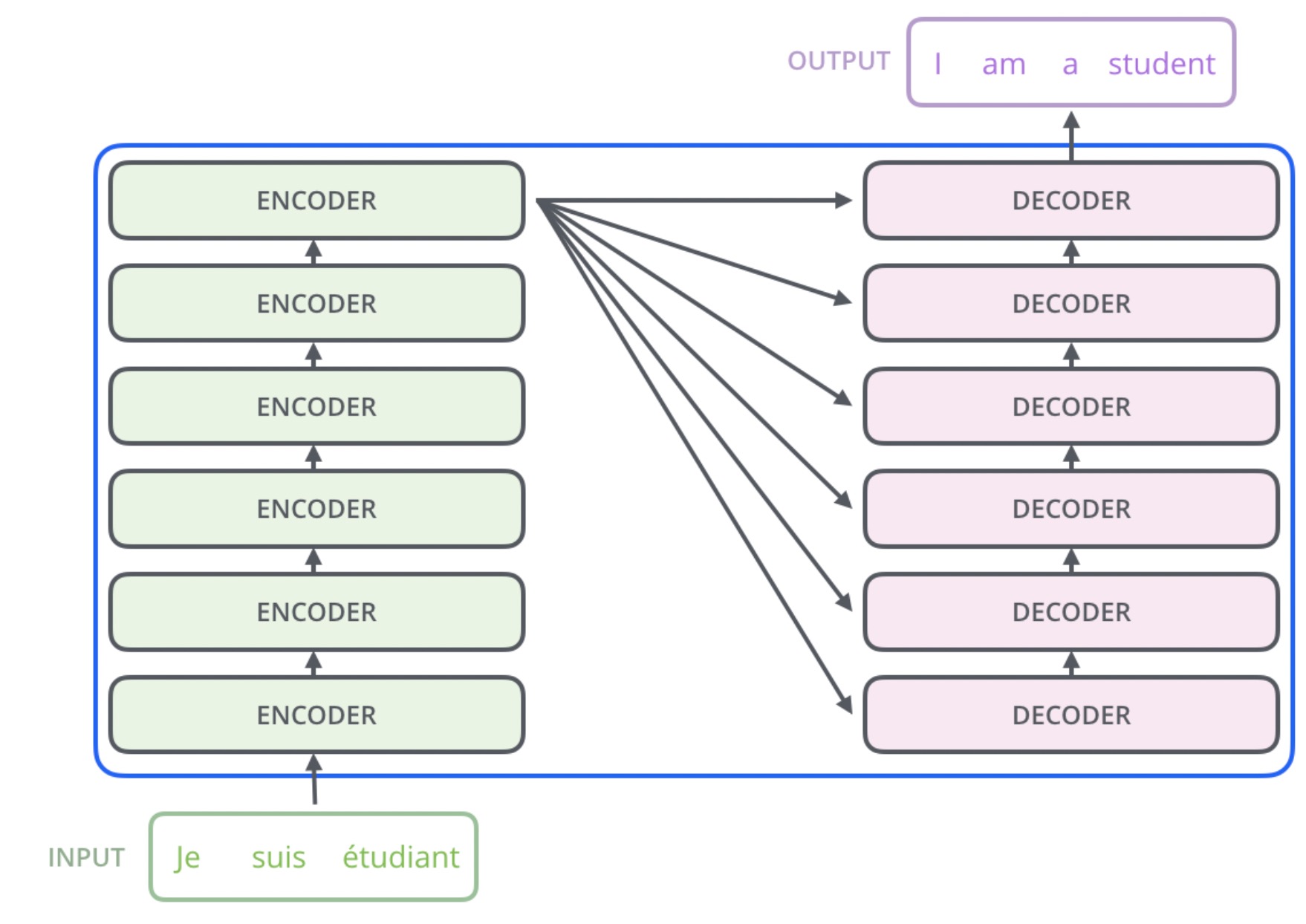
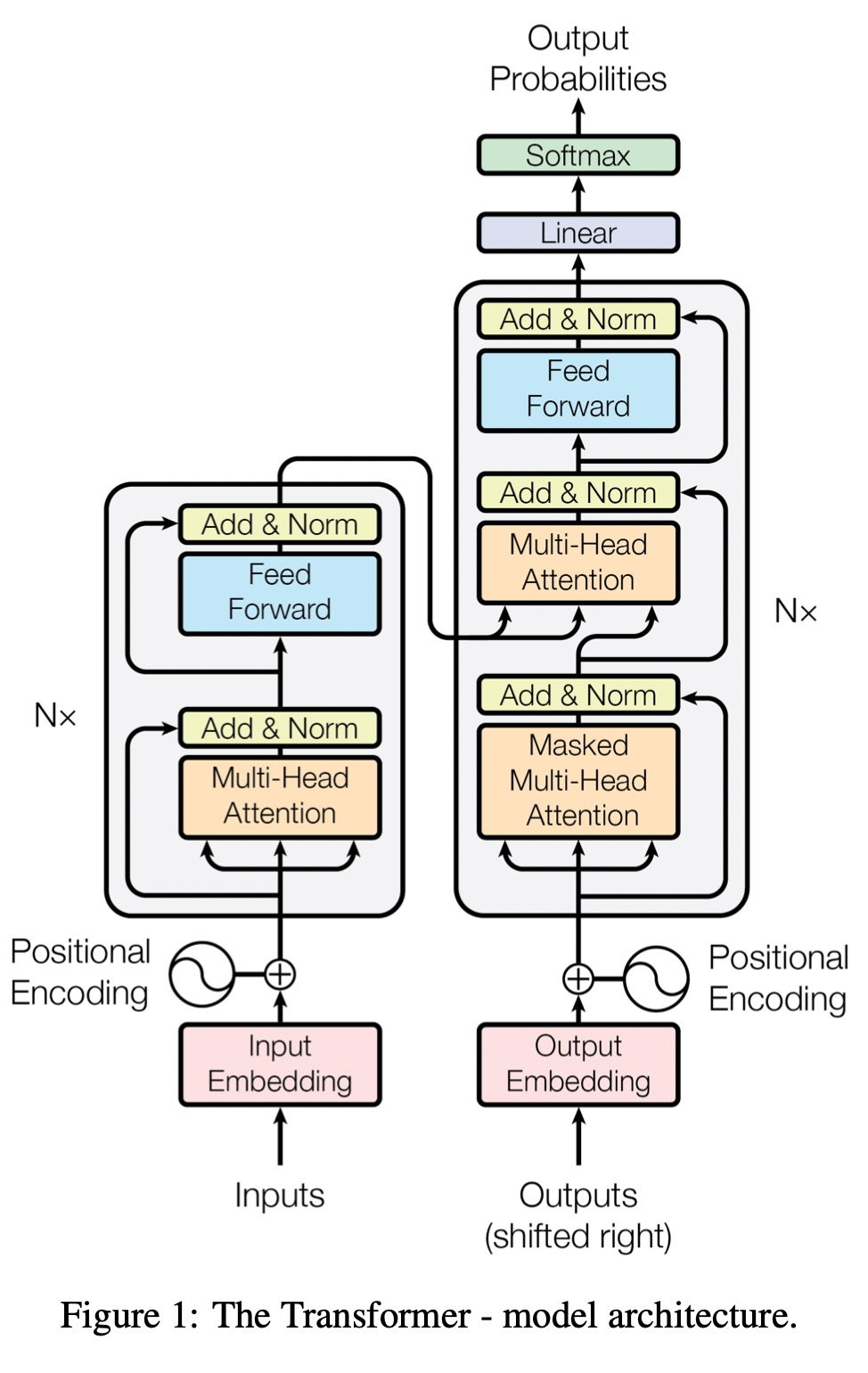
Structure
Encoder
The encoder consists of 6 identical layers. Each layer consists of two sub-layers: 1. Multihead self-attention 2. Feed forward fully connected network
residual connection (skip connection) are employed around each of the two sub-layers followed by layer normalization. The output of each sub-layer is:
\[\text{LayerNorm}(x + \text{Sublayer}(x))\]
Where \(\text{Sublayer}(x)\) is the function implemented by the sub-layer itself. All sub-layers and embedding layers have output of dimension \(d_{model} = 512\)
Decoder
The decoder consists of 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack as key, value and the previous decoder output as query. The first self-attention sub-layer is modified to mask the future during training, this ensures that the predictions for position \(i\) can depend only on the known outputs at positions less than \(i\).
Self Attention
Given input \(X \in \mathbb{R}^{n_b \times n_s \times d_{model}}\) and trainable parameters \(W_q \in \mathbb{R}^{d_{model} \times d_{k}}, W_k \in \mathbb{R}^{d_{model} \times d_{k}}, W_v \in \mathbb{R}^{d_{model} \times d_{v}}\), matrices query \(Q \in \mathbb{R}^{n_b \times n_s \times d_k}\), key \(K \in \mathbb{R}^{n_b \times n_s \times d_k}\), value \(V \in \mathbb{R}^{n_b \times n_s \times d_v}\) are defined as:
\[Q = XW_q, \;\; K = XW_k, \;\; V = XW_v\]
Scaled Dot-Product Attention
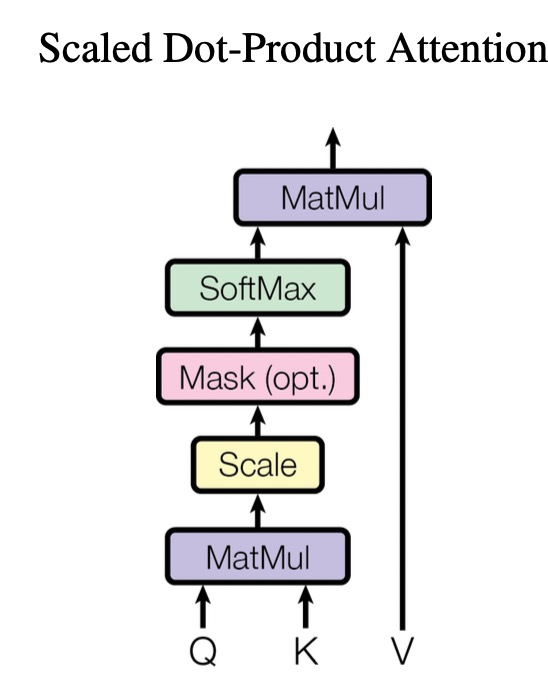
\[\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}}) V\]
The scale is used to prevent the large magnitude of the dot product so that the gradient of softmax vanishes.
Multi-head Self Attention
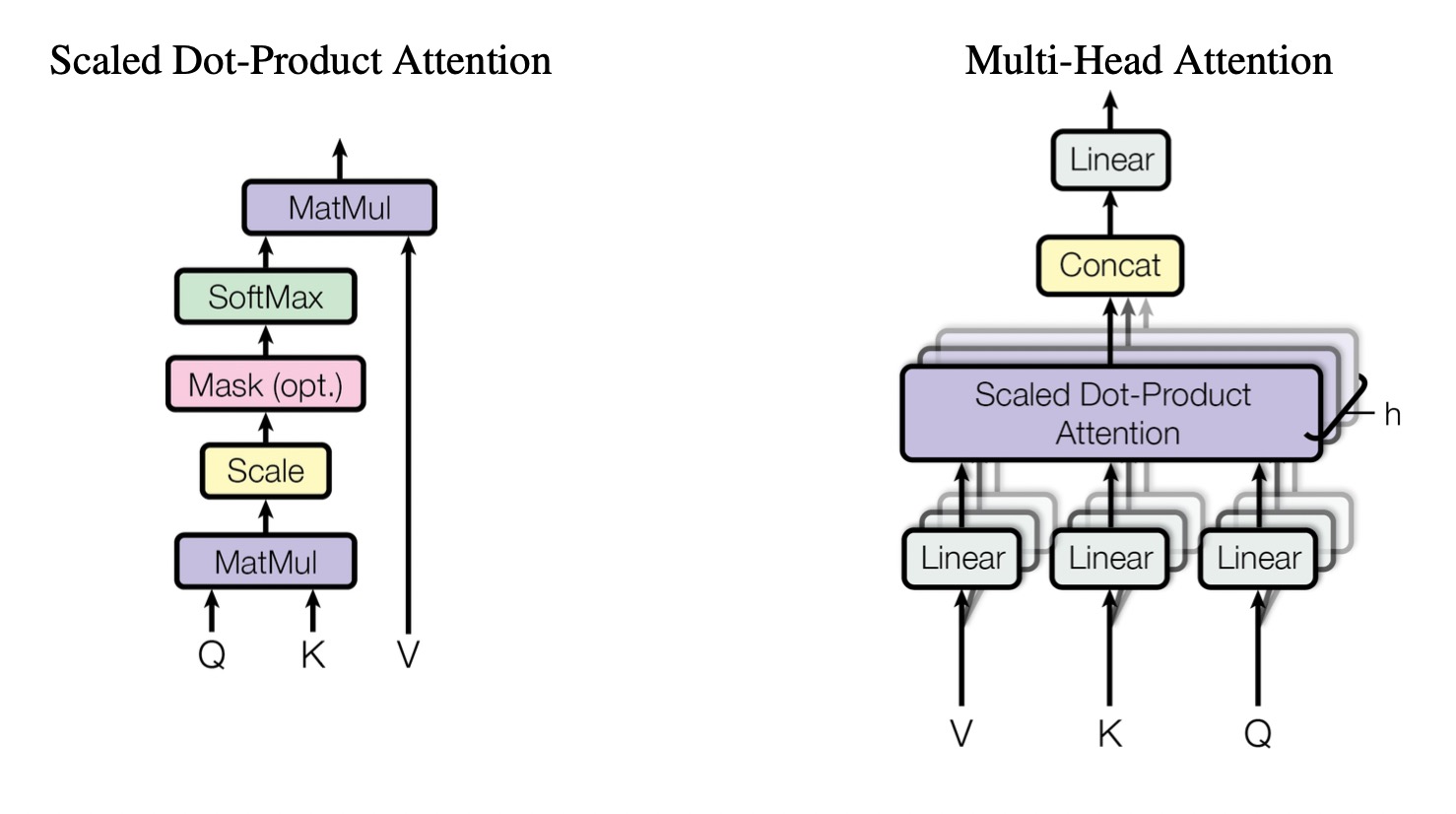
Instead of using a single attention function, \(h\) of parallel attention functions with different \(W^q_i, W^k_i, W^v_i\) are used and concatenated into single self attention matrix. The final self attention matrix is then multiplied by a weight matrix \(W_o \in \mathbb{R}^{hd_v \times d_{model}}\):
\[\text{MultiHead} (Q, K, V) = \text{Concat} (\text{head}_1, ...., \text{head}_h) W_o\]
Where
\[\text{head}_i = \text{Attention}(QW^Q_i, KW^k_i, VW^V_i)\]
In this paper \(h = 8, d_{model} = 512, d_{model} / h = d_k = d_v = 64\) and in a multi-head self-attention layer, all the keys, values and queries come from same place which is the output of the previous layer in the encoder. (i.e \(Q = K = V = X\) where \(X\) is the output from previous layer)
Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in the encoder and decoder contains a fully connected feed-forward network. This consists of two linear transformations with a ReLU activation in between:
\[\text{FFN}(\mathbf{x}) = max(0, \mathbf{x} W_1 + \mathbf{b}_1) W_2 + \mathbf{b}_2\]
The parameters are different for different layers. The dimensionality of input and output is \(d_{model} = 512\), and the inner-layer has dimensionality \(d_{ff} = 2048, W_1 \in \mathbb{R}^{502 \times 2048}, W_2 \in \mathbf{2048 \times 502}\)
Positional Encoding
Since the model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. Thus, we add positional encodings to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension \(d_{model}\) as the embeddings, so that the two can be summed:
\[PE_{(pos, 2i)} = \sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\] \[PE_{(pos, 2i+1)} = \cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\]
Where \(i\) is the dimension, \(pos\) is the position. For example \(PE(1) = [\sin(\frac{1}{10000^{\frac{0}{d_{model}}}}), \cos(\frac{1}{10000^{\frac{2}{d_{model}}}}), \sin(\frac{1}{10000^{\frac{4}{d_{model}}}}) ....]\)
It has several properties:
- For each time-step, it outputs a unique encoding.
- The distance between two time-steps is consistent across sentences with different lengths.
- Deterministic
- \(PE_{pos+k}\) can be represented linearly using \(PE_{pos}\), so it generalizes easily to unseen length sequences.
Ref
https://jalammar.github.io/illustrated-transformer/
https://theaisummer.com/self-attention/
https://zhuanlan.zhihu.com/p/98641990
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/#the-intuition